
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MMSFLHIVFSILVVVAFILGNFANGFIALINFIAWVKRQKISSADQIIAALAVSRVGLLWVILLHWYSTVLNPTSSNLKVIIFISNAWAVTNHFSIWLATSLSIFYLLKIVNFSRLIFHHLKRKAKSVVLVIVLGSLFFLVCHLVMKHTYINVWTEECEGNVTWKIKLRNAMHLSNLTVAMLANLIPFTLTLISFLLLIYSLCKHLKKMQLHGKGSQDPSTKIHIKALQTVTSFLILLAIYFLCLIISFWNFKMRPKEIVLMLCQAFGIIYPSFHSFILIWGNKTLKQTFLSVLWQVTCWAKGQNQSTP | |
| CCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHSSSCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHSSSSCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCSSSSSSCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHCCCHHHHHHHHHHHHHCCCCCCCCCCCCC | |
| 975899999999999999999999999999999999369887787999999999999999999858604248434647789999999999929999999999999715642789789999999964449999999999999999999852100047788852466532125999999999999999999999999999999999999861879999999729999999999999999999999999999998536658999999999998488745988608759999999999866002078588998 |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | |
| | | | | | | | | | | | | | | | | |
| MMSFLHIVFSILVVVAFILGNFANGFIALINFIAWVKRQKISSADQIIAALAVSRVGLLWVILLHWYSTVLNPTSSNLKVIIFISNAWAVTNHFSIWLATSLSIFYLLKIVNFSRLIFHHLKRKAKSVVLVIVLGSLFFLVCHLVMKHTYINVWTEECEGNVTWKIKLRNAMHLSNLTVAMLANLIPFTLTLISFLLLIYSLCKHLKKMQLHGKGSQDPSTKIHIKALQTVTSFLILLAIYFLCLIISFWNFKMRPKEIVLMLCQAFGIIYPSFHSFILIWGNKTLKQTFLSVLWQVTCWAKGQNQSTP | |
| 733323321132133123313321220021001110453303100100000020000001113320000001031233200000100112222300100000000000000213110000013303210011013122323312111303231324434111113131332220111133333333233113313320220022023203433444411314001200200121232333233112211011313442001010122002102300000011043014002300210101146564668 |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHSSSCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHSSSSCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCSSSSSSCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCHHHHHHHHHHHHHHHHHHHHHHHCCCHHHHHHHHHHHHHCCCCCCCCCCCCC MMSFLHIVFSILVVVAFILGNFANGFIALINFIAWVKRQKISSADQIIAALAVSRVGLLWVILLHWYSTVLNPTSSNLKVIIFISNAWAVTNHFSIWLATSLSIFYLLKIVNFSRLIFHHLKRKAKSVVLVIVLGSLFFLVCHLVMKHTYINVWTEECEGNVTWKIKLRNAMHLSNLTVAMLANLIPFTLTLISFLLLIYSLCKHLKKMQLHGKGSQDPSTKIHIKALQTVTSFLILLAIYFLCLIISFWNFKMRPKEIVLMLCQAFGIIYPSFHSFILIWGNKTLKQTFLSVLWQVTCWAKGQNQSTP | |||||||||||||||||||||||||
| 1 | 4djhA | 0.11 | 0.21 | 0.89 | 1.37 | Download | -SPAIPVIITAVYSVVFVVGLVGNSLVMFVIIR----TKMKTATNIYIFNLALADALVTTTMPFQSTVYLMNSWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKA----LDFRTPLKAKIINICIWLLSSSVGISAIVLGGTKVREDVDVIECSLQFPDWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLLSDR-----------NLRRITRLVLVVVAVFVVCWTPIHIFILVEALGSALSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCF-------------P | |||||||||||||||||||
| 2 | 5tjvA | 0.11 | 0.20 | 0.89 | 2.80 | Download | LNPSQQLAIAVLSLTLGTFTVLENLLVLCVILHS--RSLRCRPSYHFIGSLAVADLLGSVIFVYSFIDFHVFHRKDSRNVFLFKLGGVTASFTASVGSLFLAAIDRYISIHRPLAYKRIVTRPKAVVAFCLMWTIAIVIAVLPLLGWNCEKLQSVCSDIFPHI---------DETYLMFWIGVTSVLLLFIVYAYMYILWKAGKRAMSFSD--------QARMDIRLAKTLVLILVVLIICWGPLLAIMVYDVFGKMKTVFAFCSMLCLLNSTVNPIIYALRSKDLRHAFRSMF--------------- | |||||||||||||||||||
| 3 | 4djhA | 0.11 | 0.21 | 0.88 | 2.08 | Download | -SPAIPVIITAVYSVVFVVGLVGNSLVMFVIIRY--TKMK-TATNIYIFNLALADALVTTTMPFQSTVYLMNSWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVCHKALD------FRTPLKAKIINICIWLLSSSVGISAIVLGGTKVREDVDVIECSLQFPWWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLL-------------RNLRRITRLVLVVVAVFVVCWTPIHIFILVEALGAALSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCFP------------- | |||||||||||||||||||
| 4 | 4ib4 | 0.12 | 0.21 | 0.91 | 1.54 | Download | EQGNKLHWAALLILMVIIPTIGGNTLVILAVSLEKK---LQYATNYFLMSLAVADLLVGLFVMPIALLTIMFEMWPLPLVLCAWLFLDVLFSTASIWHLCAISVDRYIAIKKPIQAN-QYNSRATAFIKI---TVVWLIIGIAIPVPIGIEITCV-L---TKER-----FGDFML--FGSLAAFFTPLAIMIVTYFLTIHALQKKAADLEDNWAYLQTISNEQRASKVLGIVFFLFLLMWCPFFITNITLVLCDTTLQMLLEIFVWIGYVSSGVNPLVYTLFNKTFRDAFGRYITCNYR---------- | |||||||||||||||||||
| 5 | 5glh | 0.12 | 0.23 | 0.88 | 1.16 | Download | IKETFKYINTVVSCLVFVLGIIGNSTLLYIIYK--------NGPNILIASLALGDLLHIVIAIPINVYKLLAEWPFGAEMCKLVPFIQKASVGITVLSLCALSIDRYRAVAS---W-----------WTAVEIVLIWVVSVVLAVPEAIGFDIITMDYKLRICLLHPVQKFMQFYDWWLFSFYFCLPLAITAFFYTLMTCEMLRKNEGLRLTWDAYLNDHLKQRREVAKTVFCLVLVFALCWLPLHLARIKLTLYNNLVLDYIGINMASLNSCANPIALYLVSKRFKNAFKSAL--------------- | |||||||||||||||||||
| 6 | 4djhA | 0.11 | 0.21 | 0.89 | 1.50 | Download | ---AIPVIITAVYSVVFVVGLVGNSLVMFVIIRY---TKMKTATNIYIFNLALADALVTTTMPFQSTVYLMNSWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKA----LDFRTPLKAKIINICIWLLSSSVGISAIVLGGTKVREDVDVIECSLQFSWWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLLSD-----------RNLRRITRLVLVVVAVFVVCWTPIHIFILVEALGAALSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCFP------------- | |||||||||||||||||||
| 7 | 4djh | 0.13 | 0.16 | 0.92 | 1.71 | Download | --PAIPVIITAVYSVVFVVGLVGNSLVMFVIIR---YTKMKTATNIYIFNLALADALVTTTMPFQSTVYLMNSWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVCHPVKALDFRTPLKAKIINICIWLLSSSVGISAIVLGGTKVREDVDV--IECSLQFPDDDWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLLSGNAYREKDRNLRRITRLVLVVVAVFVVCWTPIHIFILVEALG---SAALSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCF-------------- | |||||||||||||||||||
| 8 | 4buoA | 0.14 | 0.18 | 0.91 | 2.56 | Download | TDIYSKVLVTAIYLALFVVGTVGNSVTLFTLAR---KKSLQSTVDYYLGSLALSDLLILLLVELYNFIWVHHPWAFGDAGCRGYYFLRDACTYATALNVVSLSVELYLAICHPFKAKTLMSRSRTKKFISAIWLASALLAIP-----MLFTMGLQNLSGDGVCTPIVDTATLKVVIQVNTFMSFLFPMLVASILNTVIANKLTVMVHQ-----PGRVQALRRGVLVLRAVVIAFVVCWLPYHVRRLMFCYISDEQWTHYFYMLTNALVYVSAAINPILYNLVSANFRQVFLSTL--------------- | |||||||||||||||||||
| 9 | 4djhA | 0.11 | 0.21 | 0.89 | 1.44 | Download | -SPAIPVIITAVYSVVFVVGLVGNSLVMFVIIR----TKMKTATNIYIFNLALADALVTTTMPFQSTVYLMNSWPFGDVLCKIVLSIDYYNMFTSIFTLTMMSVDRYIAVC---HPVKA-LDFRTPLKAKIINICIWLLSSSVGISAIVLGGTKVREDVDVIECSLQFPWWDLFMKICVFIFAFVIPVLIIIVCYTLMILRLKSVRLLSD-----------RNLRRITRLVLVVVAVFVVCWTPIHIFILVEALGSALSSYYFCIALGYTNSSLNPILYAFLDENFKRCFRDFCF-------------P | |||||||||||||||||||
| 10 | 3aymA | 0.11 | 0.21 | 0.97 | 1.55 | Download | VPDAVYYSLGIFIGICGIIGCGGNGIVIYLFTK----TKSLTPANMFIINLAFSDFTFSLVNGFPLMTISCFLKIFGFAACKVYGFIGGIFGFMSIMTMAMISIDRYNVIGRPMAASK----KMSHRRAFIMIIFVWLWSVLWAIGPIFGWGAYTLEGVLCNCSYISRDSTTRSNILCMFILGFFGPILIIFFCYFNIVMSVSNHEKEMAAMAKRLNAKEANAEMRLAKISIVIVSQFLLSWSPYAVVALLAQFGPTPYAAQLPVMFAKASAIHNPMIYSVSHPKFREAISQTFPWVLTCCQFDETEIP | |||||||||||||||||||
| ||||||||||||||||||||||||||
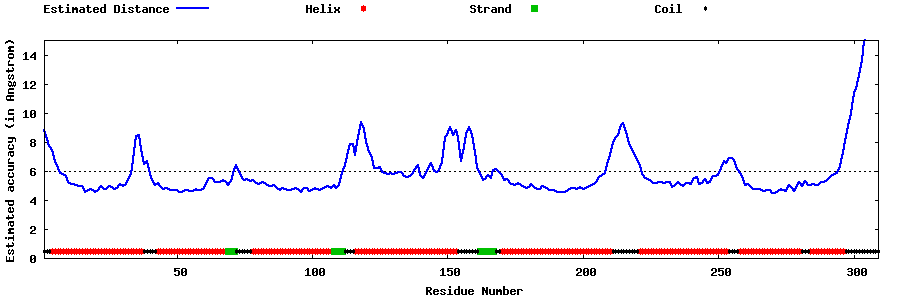
| Generated 3D models | Estimated local accuracy of models | ||
 | |||
|
|
|||
 | |||
|
| |||
 | |||
|
| |||
 | |||
|
| |||
 | |||
|
| |||
