GPCR-I-TASSER results for P0C626
[Click on P0C626_results.tar.bz2 to download the tarball file including all modeling results listed on this page]
| Submitted Sequence |
| >P0C626 MEDKNQTVVTEFLLLGLTDHPYQKIVLFFMFLFVYLITLGGNLGMITLIWIDPRLHTPMY FFLRHLSFVDICSSSSVVPKMLCNIFAEKKDITFLGCAAQMWFFGLFEAAECFLLAAMAY DRYVAICKPLLYTLIMSQQVCMQLVVGPYAMALISTMTHTIFTFCLPFCGSNIINHFFCD IFPLLSLACADTWVNKFVLFVLAGAIGVLSGLIIMVSYICILMTILKIQTADGKQKAFFT CFSHLAAVSILYGTLFLIYVRPSSSSSLGIYKVISLFYTVVIPMVNPLIYSLRNKEVKDA FRRKIERKKFIIGR |
| Predicted Secondary Structure |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | MEDKNQTVVTEFLLLGLTDHPYQKIVLFFMFLFVYLITLGGNLGMITLIWIDPRLHTPMYFFLRHLSFVDICSSSSVVPKMLCNIFAEKKDITFLGCAAQMWFFGLFEAAECFLLAAMAYDRYVAICKPLLYTLIMSQQVCMQLVVGPYAMALISTMTHTIFTFCLPFCGSNIINHFFCDIFPLLSLACADTWVNKFVLFVLAGAIGVLSGLIIMVSYICILMTILKIQTADGKQKAFFTCFSHLAAVSILYGTLFLIYVRPSSSSSLGIYKVISLFYTVVIPMVNPLIYSLRNKEVKDAFRRKIERKKFIIGR | |
| CCCCCCCCCSSSSSSCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHCCCCCCCCHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCCCCCHHHHHHCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCHHHCHHHHHHHHHHHHHHHSSSSSCCCCCCCCCCCCSSSSSSCCCHHCCCCHHHCCCCHHHHHHHHHHHHHHSSCCCC | |
| 99988732314578648999360899999999999999998979999985188877748888767998835721257088989871489788589999999999999999999999997541340062201880167889999999999999999999999984540889991384416808887770468627678888898999999999999999999999812667576754311558889979999742224584789998787898899883210312435644046598999999999655230469 |
| Predicted Solvent Accessibility |
| 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | MEDKNQTVVTEFLLLGLTDHPYQKIVLFFMFLFVYLITLGGNLGMITLIWIDPRLHTPMYFFLRHLSFVDICSSSSVVPKMLCNIFAEKKDITFLGCAAQMWFFGLFEAAECFLLAAMAYDRYVAICKPLLYTLIMSQQVCMQLVVGPYAMALISTMTHTIFTFCLPFCGSNIINHFFCDIFPLLSLACADTWVNKFVLFVLAGAIGVLSGLIIMVSYICILMTILKIQTADGKQKAFFTCFSHLAAVSILYGTLFLIYVRPSSSSSLGIYKVISLFYTVVIPMVNPLIYSLRNKEVKDAFRRKIERKKFIIGR | |
| 85652303001000000043240100001303331321333331001001000300000010020000100100000002000200254220101000000100000020001000000000000001112020300330000001201110130030101100302004412010000032100200013231101100210132233133103303310120001031462231000011102100102320110000003253134441000021032003300300002132014003200432200238 | |
| Values range from 0 (buried residue) to 9 (highly exposed residue) | |
| Predicted normalized B-factor |

| Top 10 templates used by GPCR-I-TASSER |
| Rank | PDB Hit | Iden1 | Iden2 | Cov. | Norm. Z-score | Download Align. | 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 | | | | | | | | | | | | | | | | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sec.Str Seq | CCCCCCCCCSSSSSSCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHHCCCCCCCCHHHHHHHHCCCCSSCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHCCCCCCCCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCCCCCCCHHHHHHCCCCCCHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHSSCCCCCCCCCHHHCHHHHHHHHHHHHHHHSSSSSCCCCCCCCCCCCSSSSSSCCCHHCCCCHHHCCCCHHHHHHHHHHHHHHSSCCCC MEDKNQTVVTEFLLLGLTDHPYQKIVLFFMFLFVYLITLGGNLGMITLIWIDPRLHTPMYFFLRHLSFVDICSSSSVVPKMLCNIFAEKKDITFLGCAAQMWFFGLFEAAECFLLAAMAYDRYVAICKPLLYTLIMSQQVCMQLVVGPYAMALISTMTHTIFTFCLPFCGSNIINHFFCDIFPLLSLACADTWVNKFVLFVLAGAIGVLSGLIIMVSYICILMTILKIQTADGKQKAFFTCFSHLAAVSILYGTLFLIYVRPSSSSSLGIYKVISLFYTVVIPMVNPLIYSLRNKEVKDAFRRKIERKKFIIGR | |||||||||||||||||||||||||
| 1 | 4iaqA | 0.16 | 0.21 | 0.84 | 2.20 | Download | ------------YIYQDSISLPWKVLLVMLLALITLATTLSNAFVIATVYRTRKLHTPANYLIASLAVTDLLVSILVMPISTMYTVTGR----WVVCDFWLSSDITCCTASIWHLCVIALDRYWAITDAVEYSAKRTPKRAAVMIALVWVFSISISL---------PPCVVN------------------TDHILYTVYSTVGAF--YFPTLLLIALYGRIYVEARSRIIQLMAARERKATKTLGIILGAFIVCWLPFFIISLVMPIHLAIFDFFTWLGYLNSLINPIIYTMSNEDFKQAFHKLIRFK------ | |||||||||||||||||||
| 2 | 3emlA | 0.18 | 0.21 | 0.88 | 3.73 | Download | --------------------IMGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS---GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAI-IVGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHVL--RQ | |||||||||||||||||||
| 3 | 3uonA | 0.18 | 0.23 | 0.88 | 2.57 | Download | --------------------TFEVVFIVLVAGSLSLVTIIGNILVMVSIKVNRHLQTVNNYFLFSLACADLIIGVFSMNLYTLYTVIGYWPLGPVVCDLWLALDYVVSNASVMNLLIISFDRYFCVTKPLTYPVKRTTKMAGMMIAAAWVLSFILWAPAILFWQFIV--GVRTVEDGECYIQFFS---------NAAVTFGTAIAAFYLPVIIMTVLYWHISRASKSRINISREKKVTRTILAILLAFIITWAPYNVMVLINTFCCIPNTVWTIGYWLCYINSTINPACYALCNATFKKTFKHLLM-------- | |||||||||||||||||||
| 4 | 4buoA | 0.16 | 0.18 | 0.89 | 2.08 | Download | -------N-SD---LDVNTDIYSKVLVTAIYLALFVVGTVGNSVTLFTLARKKS---TVDYYLGSLALSDLLILLLAMPVELYNFIWVHWAFGDAGCRGYYFLRDACTYATALNVVSLSVELYLAICHPFKAKTLMSRSRTKKFISAIWLASALLAIPMLFTMGQNLSGDGTHPGGLVCTP-------IVDTATLKVVIQVNTFMSFLFPMLVASILNTVIANKLTVMV--PGRVQALRRGVLVLRAVVIAFVCLMFCYISD-EQWTTFLFDFYHYFYMYVSAAINPILYNLVSANFRQVFLSTL--------- | |||||||||||||||||||
| 5 | 3emlA | 0.19 | 0.21 | 0.88 | 4.02 | Download | ---------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAIT--ISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALCWLPLHIINCF-TFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSHV--LRQ | |||||||||||||||||||
| 6 | 4bvnA | 0.17 | 0.21 | 0.88 | 2.98 | Download | ------------------LSQQWEAGMSLLMALVVLLIVAGNVLVIAAIGSTQRLQTLTNLFITSLACADLVVGLLVVPFGATLVVRGTWLWGSFLCELWTSLDVLCVTASVETLCVIAIDRYLAITSPFRYQSLMTRARAKVIICTVWAISALVSFLPIMMHWW----RDEDPQALKCYQD----PGCCDFVTNRAYAIASSIISFYIPLLIMIFVALRVYREAKEQ---MREHKALKTLGIIMGVFTLCWLPFFLVNIVNNRDLVPKWLFVAFNWLGYANSAMNPIILC-RSPDFRKAFKRLLA-------- | |||||||||||||||||||
| 7 | 4ea3A | 0.17 | 0.22 | 0.83 | 2.81 | Download | -------------------PLGLKVTIVGLYLAVCVGGLLGNCLVMYVILRHTKMKTATNIYIFNLALADTLVLLT-LPFQGTDILLGFWPFGNALCKTVIAIDYYNMFTSTFTLTAMSVDRYVAICHPTSSKAQAVNVAIWALASVVGVPVAIMGSAQVEDEIECLVEIPTPQDYWGPVFAICIFLFSF-----------------IVPVLVISVCYSLMIRRLRGVRLLSGSVAVFVGCWTPVQVFVLAQGLG-----VQPSSETAVAILRFCTALGYVNSCLNPILYAFLDENFKACFR------------ | |||||||||||||||||||
| 8 | 3emlA | 0.19 | 0.21 | 0.88 | 5.86 | Download | ----------------------ISSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS---GFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFEDVVP-----------MNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQLVHAAKSLAII-VGLFALCWLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSH--VLRQ | |||||||||||||||||||
| 9 | 3emlA | 0.19 | 0.21 | 0.89 | 5.58 | Download | I--------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAIT--ISTGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLNCGQSQGCGEGQVACLFEDVVPMNYMVYFNFFACVLVPL-----------LLMLGVYLRIFLAARRQLVHAAKSLAIIVGLFALC-WLPLHIINCFTFFCPDCSHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKIIRSH--VLRQ | |||||||||||||||||||
| 10 | 3emlA | 0.16 | 0.21 | 0.85 | 2.80 | Download | ---------------------MGSSVYITVELAIAVLAILGNVLVCWAVWLNSNLQNVTNYFVVSLAAADIAVGVLAIPFAITIS--TGFCAACHGCLFIACFVLVLTQSSIFSLLAIAIDRYIAIRIPLRYNGLVTGTRAKGIIAICWVLSFAIGLTPMLGWNNCGQSQGCGEGQVACLFEDV--------VPMNYMVYFNFFACVLVPLLLMLGVYLRIFLAARRQ-----LVHAAKSLAIIVGLFALCWLPLHIINCFTFFCHAPLWLMYLAIVLSHTNSVVNPFIYAYRIREFRQTFRKI---------- | |||||||||||||||||||
| ||||||||||||||||||||||||||
| Top 5 Models predicted by GPCR-I-TASSER |
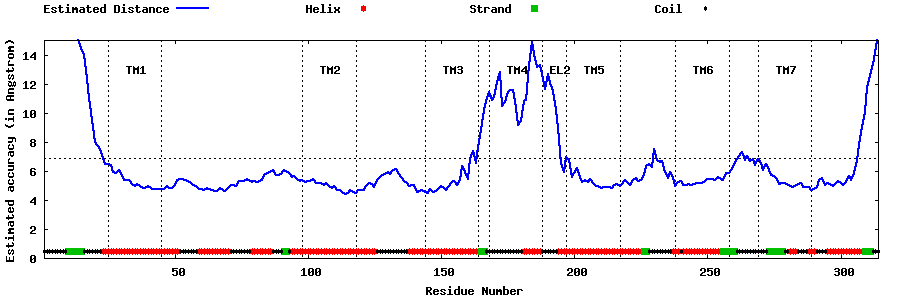
| Generated 3D models | Estimated local accuracy of models | ||
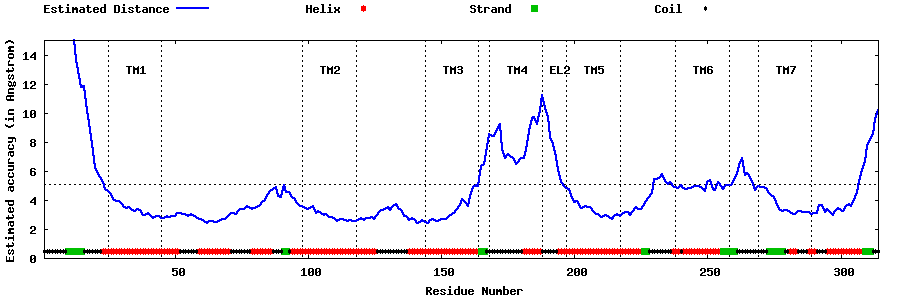 | |||
|
|
|||
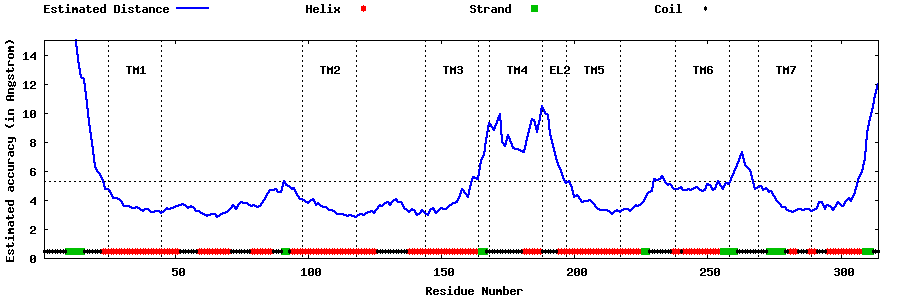 | |||
|
| |||
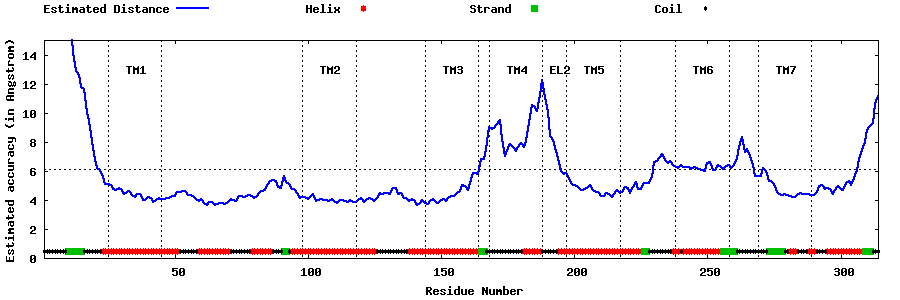 | |||
|
| |||
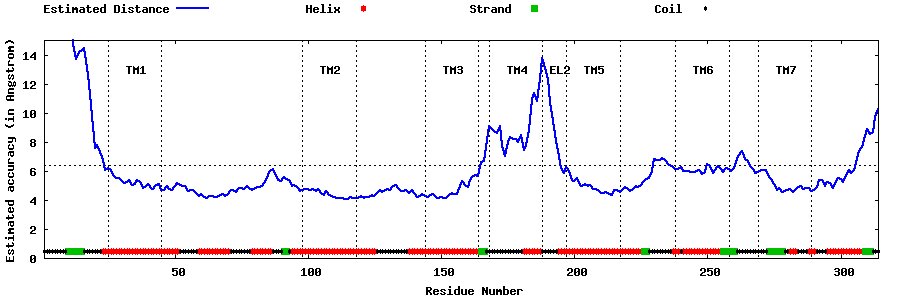 | |||
|
| |||
 | |||
|
| |||
| Please cite following articles when you use the GPCR-I-TASSER server: | |
| J Zhang, J Yang, R Jang, Y Zhang. Hybrid structure modeling of G protein-coupled receptors in the human genome, submitted (2015). |